GPU
Computing Labs
 Assignment mini-project 2026
Assignment mini-project 2026
Goal: Develop
and study some simple kernels and their performance
Deliverables:
report + code
Deadline: Friday 27
March
- Choose one/two basic operations that you will apply on 1 or 2
arrays
- addition - multiplication - mul-add - division - sqrt -
max - bitwise operation (and) - ...
- Choose one/two datatype: integer, float, double
- Choose and compare either two basic operations
(e.g. compare multiplication and division) or two different
datatypes (e.g. compare float and double).
- 1. Measure the computational and memory performance in
function of the array size (automate this!)
- performance will converge to its maximum
- it will be memory-bound, so constrained by the memory
bandwidth
- 2. Let the kernel execute on multiple elements
- 3. Artificially increase the compute intensity by doing more
of the same operation on the same data
- Add a loop over the operation and/or use the idea of a
pseudo-random number generator (see this code)
- The compute intensity will depend on the loop count which
you specify as a parameter
- By doing so, the computational performance will increase as
is demonstrated by the roofline model
- Draw the roofline model (which is hardware dependent) for
the operation and the GPU
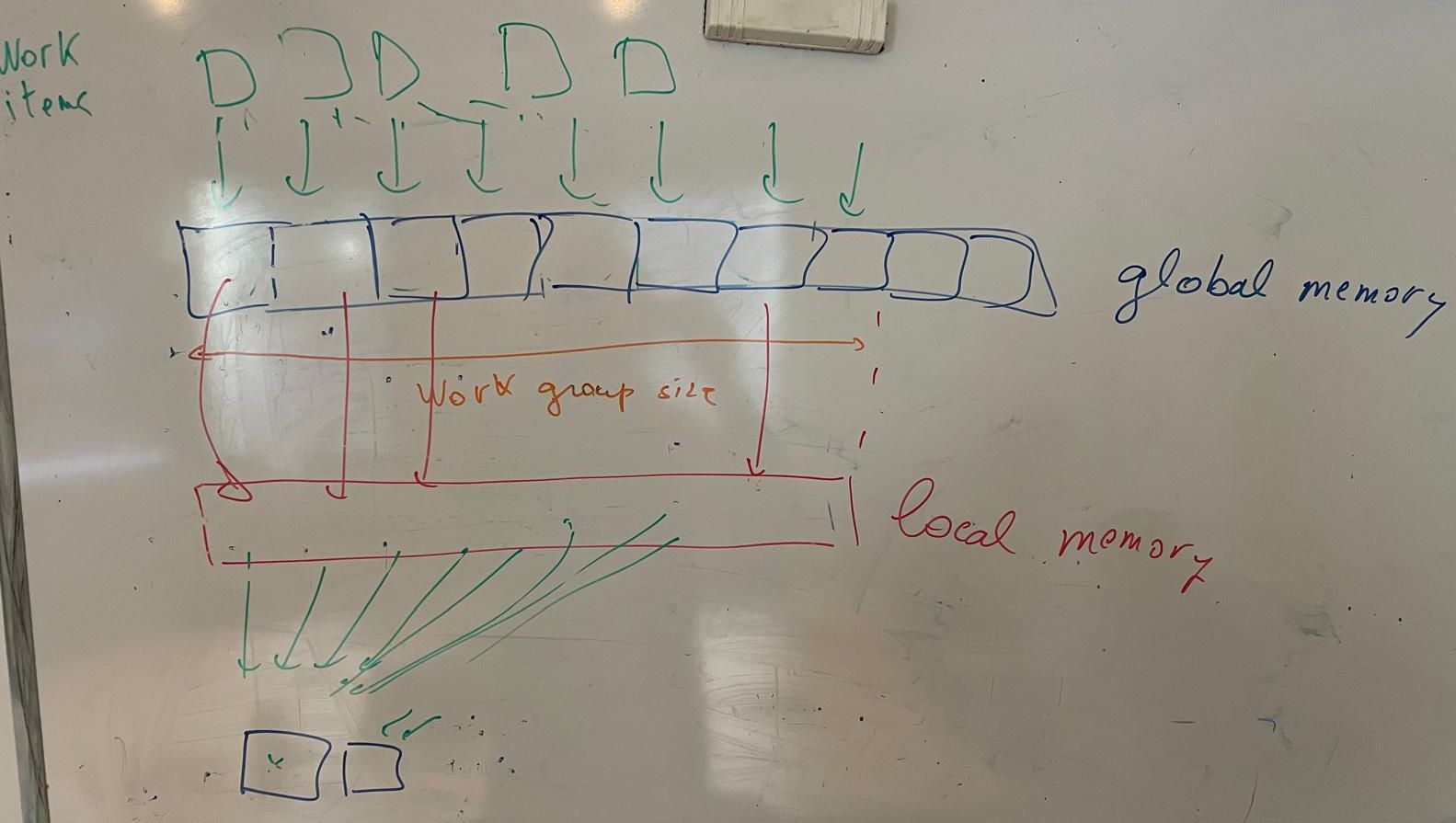
- 4. Each kernel (work item) uses the data of the whole work
group.
- Compare a version that works with the data in global memory
with a version that copies the data to local memory
- See this
scheme
- Specify which GPU you are using, its parameters (generation,
#multiprocessors, #scalar processors on each multiprocessor,
frequency, ...) and calculate the theoretical peak performance
- Several characteristics can be queried with cuda.
- With the compute capability you know of which generation
your gpu is (see lesson 3 or wikipedia)
- Use the benchmark app of www.gpuperformance.org
to empirically measure the peak performance (computational and
memory)
- By clicking on the data you'll see the measurements (or
roofline)
- Compare the performances (theoretical, benchmark, kernels) and
try to explain them
- Hint: check 'Add a new project to cmake' on the
documentation page.
- Consider the applied rules
for the use of AI.
- Back to top -
{kind=link}