GPU Computing
Project
GOAL:
implement an algorithm on GPU, analyze, model its performance
and optimize it.
Topics
You are free in choosing a topic. For instance, you can parallelize
the algorithm of your thesis, or another one that interests you.
Discuss your choice with the professor.
Inspiration can be found in the project section of
the PPP course and below you also find GPU-specific topics.
-
Test and use one of the
alternative programming approaches discussed in lesson 6,
instead of OpenCL.
-
Ask the professor for
permission (mandatory! if no permission, project is
refuted)
-
Make sure it compile and
runs on ETRO's GPUFarm.
Objectives
For a (frequently occurring) computational problem you should
develop an efficient GPU solution in OpenCL.
- Implement or get the sequential version.
- Create a naive, GPU implementation which is correct (compare
with sequential result).
- Also measure speedup, performance (flops) and bandwidth. We
advice you to make some management code (or script) that
automates this!
- Run it on ETRO's GPUFarm for the final experimental results
(mandatory!). You may add the results of running it on your own
laptop.
- Optimize the naive implementation by trying to overcome the
performance limits it contains.
- Study alternative optimizations and compare their
performance.
Make sure to invest enough time in the
comparisons and modeling. The focus is not only on the complexity
of the GPU implementation! It's better to have a less complex
implementation with a good analysis!
Organization
Here are the rules for the project:
- The project will be under the guidance of Jan Lemeire.
- You can work alone or in groups of two students.
- The deadline to choose a topic is 24th April, 2026.
- Meet us somewhere halfway the project to discuss your current
problems, to let us give advice and to define the expected end
result. Make an individual appointment.
- The deadline for the project is 3 days before the oral
defense, with ultimate deadline Sunday June 21st, for
which you plan a moment with the professor.
- During the oral defense, we'll discuss your project results,
its relation with the theory (important to assess your project
outcomes with the concepts discussed in the theory!) and you'll
get questions about the theory (counting for 30%).
See Documentation Page.
Programming and Optimization Tips: see end of lesson 5.
We expect the following deliverables:
- All relevant code related to the project.
- sequential code + parallel implementations
- the parallel versions should check their result with the one
of the sequential version to proof that the outcome is
correct!
- A short report that describes:
- The problem (brief).
- The different implementations. You can be brief here,
since we have your source code. A diagram or scheme might be
helpful here.
- Links to sources of information and of source code.
- Description of the GPUs used. Refer to the sharepoint
excel sheet.
- Most important: a discussion of the performance of the
different implementations
- Give speedups, computational performance (flops) and
bandwidth of the different experiments
- Discussion of results: compare implementations and try
to explain inefficiencies
- especially in case of bad speedups, try to find out
why it is performing so bad
Check the next section!
-
Regulations on the use of (Gen)AI
Additional topics
a) Tree Construction and Tree Traversal (can be split into 2
separate topics)
- Given a mesh of vertices (forming triangles) describing a 3D
volume:
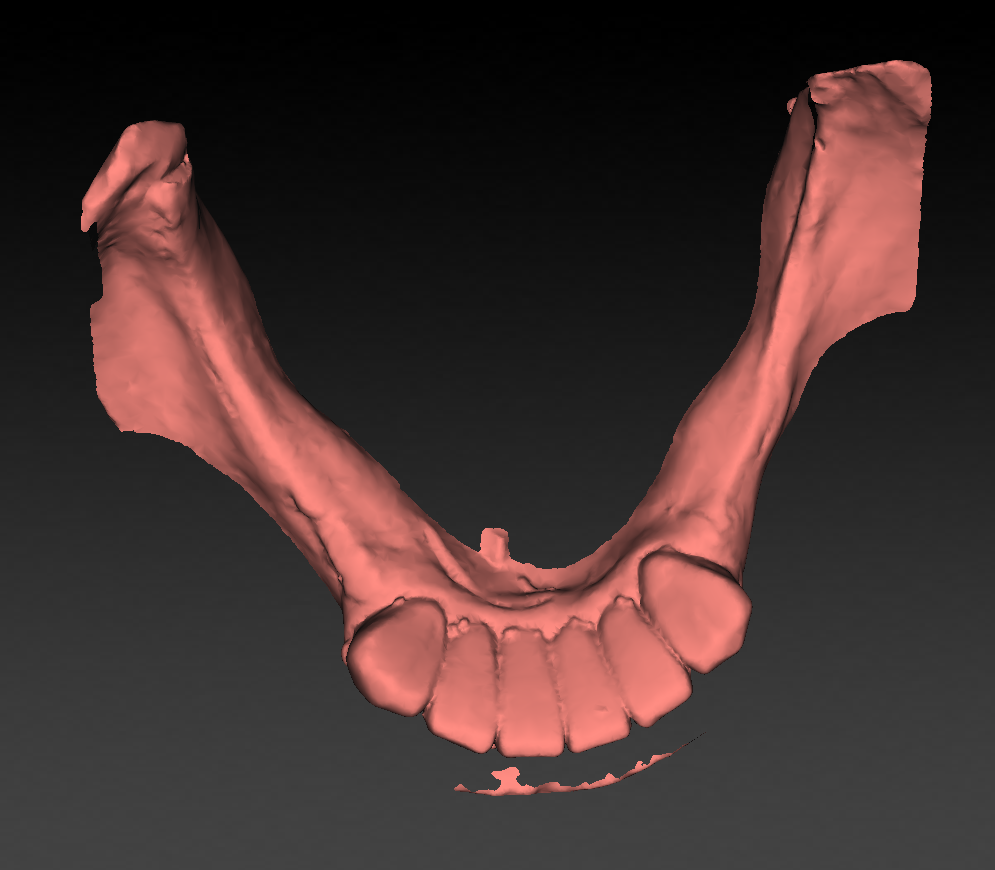
- We want to know in each point in space the distance to the
volume, i.e. the distance to the closest vertex/triangle:
- A naive way to do this is to traverse for each point in space
over all vertices and find the closest one.
- If the mesh contains about 1 million vertices and for the
space 512x512x512 points are considered, this will take ages...
- Finding the closest vertex fast happens by tree describing a
Bounding Volume Hierarchy:
- CUDA-code is provided. Use if for our problem, make it OpenCL
and think about optimizations. On a CPUquadcore i7 the above
mesh takes 15 minutes to complete... On a GPU?
- we will provide you the data.