Practica of
PPP
Visual
Studio Solution starting code
VectorElementWiseProduct: compare variants of the same
algorithm <= use this as template for the mini-project!!
- ComplexFunctions: compute-intensive functions, ideal
for making parallel tests with high granular programs
- ArrayOfFunctionsExample: how to use functions as
variables
- MultithreadingTesting
- Most other code is part of the exercises on Multithreading
explained below
 Documentation & instructions for the exercises upto the
mini-project (until OpenMP)
Documentation & instructions for the exercises upto the
mini-project (until OpenMP)
- Use the free tool
CPU-Z to check your processor's capabilities
- Check Compilers with godbolt.org/
- MSVC is the Microsoft Visual Studio compiler
- add option -O2 to see the optimizations!
- gcc (GNU) and icc (Intel) are also very prominent
compilers for x86/x64 CPUs
- Visual Studio settings:
- Choose the Release configuration
(debug doesn't get optimized).
- Project Properties -> Configuration Properties (to
be set separately for Debug & Release configurations)
- C/C++ -> Optimization -> choose Optimization
level
- you can override this configuration for each file
separately: right-click on file and choose Properties
- C/C++ -> Optimization -> enable Intrinsic
Functions: Yes or No
- C/C++ -> Output Files -> Assembler output: Assembly
With Source Code (/FAs)
- an .asm file is generated in the x64\Release
folder
- C/C++ -> Command Line -> Additional Options:
/Qpar /Qpar-report:2 /Qvec-report:2
- Assembler code (to be checked with godbolt
or generated .asm-files):
- watch out: movss xmm0
is a scalar move on a vector register, mulss is
a scalar multiplication. Scalar means working on 1
element.
- movups and mulps are
the true vector instructions!
- List
of x86 instructions
- Measure time accurately (std::chrono is a
high-precision clock since C++ 11)
- auto-parallelization
and auto-vectorization in Visual C++ (Use of pragmas)
- with #pragma loop(ivdep) you indicate
that loop iterations are independent. Sometimes this
pragma is necessary.
- x86
vector instructions
- Test the multithreading & openMP with the project
'MultithreadingTesting': it contains compute-intensive code
with which you can achieve good speedups
- Test the performance with compile options O2 and Od.
- It also show how to tell the compiler to parallelize
the code:
- with pragma hints #pragma loop(ivdep) and
#pragma loop(hint_parallel(16))
- Compiler flags in Project Properties: C/C++ ->
Command Line -> Additional Options: /Qpar
/Qpar-report:2
- The output of the compiler indicates where
parallelization was successful
- Multithreading in C++ 11, another
short tutorial
- OpenMP
in Visual C++
- Activate
OpenMP in Visual Studio: project properties ->
Configuration Properties -> C/C++ -> Language: Open
MP Support: Yes OR add in All Options
/openmp
- GPU computing for element-wise operations
(independent iterations)
- example
Visual Studio projects
- add these files to inc/JC (in
solution folder): openCLUtil (unzip in
folder inc/JC)
- Configure a project for OpenCL in the
Project properties:
- C/C++ -> additional include
directories: OpenCL include directory (where the CL
directory is) [1]
- ..\GPU OpenCL SDK\include;
- Linker
- General -> additional library
directories: directory where library OpenCL.lib
is (take the x64 version) [2]
- ..\GPU OpenCL
SDK\lib\x64;
- Input -> Additional Dependencies:
OpenCL.lib [3]
- Make sure that the
correct configuration is considered in both property
and run: “Release | x64”
- add
before the include #define
CL_USE_DEPRECATED_OPENCL_1_2_APIS
-
MPI in Visual C++ (not for the mini-project)
- Install
both: the msmpisetup.exe and msmpisdk.msi
- Counting 3s both
implementations of the theory session
- Configure,
compile and run MPI-programs
- after installation and having set the environment
variables, configuring MPI in a Visual studio project
amounts to set the following the Project Properties:
- C/C++: Additional include directories: add
$(MSMPI_INC);$(MSMPI_INC)\x64
- Linker -> General -> Additional library
directories: add $(MSMPI_LIB64)
- Linker -> input -> Additional
dependencies: add msmpi.lib
- to check the environment variables in Windows,
start cmd window:
- prints all the environment variable:
set
- create a variable: set MSMPI_LIB64='C:\Program
Files (x86)\Microsoft SDKs\MPI\Lib\x64\'
- remove a variable: set
MSMPI_LIB64=
- Microsoft
MPI Documentation
-
MPI on the VUB/ULB Hydra cluster
Mini-project on optimization (20%
of marks)
Project VectorElementWiseProduct: Study
the different optimizations and compare 2 related array
operations. Solution
Solution project
'MultithreadingTesting'
Every student or group of 2 students chooses a
different combination of 2 array operations and 2 different data
types, and send it to Jan
Lemeire for OK.
Project deadline: 08/11 Mail code +
report to Jan Lemeire
- Array operations:
- Choose 2 element-wise array operations: add - mul -
mul-add - div - sqrt - max - bitwise operation (and)
- compare for instance mul with div, or mul with mul-add
- Or choose 2 types of reductions: sum (calculates
the sum of all elements of an array), product, mul-add or
max of an array
- compare for instance sum with product (same number of
operations)
- OR Compare two different data types for the same
operation: byte (8-bit), short integer (16-bit),
integer, _int64, float, double
- put a #define TYPE float in the beginning of your
code and use TYPE everywhere. You can then change
the data type in the define.
- most of the code is generic in the type except for the
functions with vector instructions, for those you have to
write a separate function for each data type.
- A simple element-wise operation or reduction is
bandwidth-limited, which means you cannot get a lot of
speedup. To reach the computational peak performance you will
increase the number of computations in one of the
following ways.
- apply the same element-wise array operation multiple
times: the memory load will decrease, so the performance
might increase. Test with a different number of iterations.
See project VectorElementWiseIterative.
or MultithreadingTesting
- use a complex function as in project ComplexFunctions
- a pseudo-random number generator as in project PseudoRandomGenerator
- such a generator-loop is used in the project MultithreadingTesting
which results in nice speedups. If you apply the
element-wise vector operation instead, you do not get
these speedups because of the memory limits!
- if you have chosen a reduction (like a global sum),
first transform each element a number of times according
to a pseudo random generator function, before reducing it.
- any other way to have more computations per byte...
- Add and test the following optimizations/parallelizations:
- try the different optimization flags: O2 &
Od intrinsics yes/No
- Q: is there a difference with intrinsics on and off? check
the assembler code (though I noted that godbolt doesn't
always gives the same as the assembler code!)
- Try to achieve the O2-performance with manual
optimization and level Od! Can you do as good or better as
the compiler!?
- Inlining
functions: using a multiplication functions and
then inlining does not seem to change a lot, so you don't have
to do it. (the versions with functions are in
Versions_Od_NoIntrinsics.cpp)
- Try optimization pragmas: #pragma unroll, #pragma
loop(no_vector)
- they only make sense with optimization turned on (not with
Od)!
- Q: does it make a difference? take a look at the assembler
code
- manual loop unrolling
- vector instructions making
reductions with intrinsics
- pragma simd
- Howto-video
for doing the last 3 threads - Solutions-video
- manual multithreading
- GPU computing
- Tips & tricks
- Make sure to compile your final code
in Release Mode!
- Check your clock frequency via the task manager and hardcode
it in your code if the query-function doesn't give the right
result.
- I don't expect you to get to understand all details of
compiler optimization, pragmas etc. These exercises just want
to give you a feeling of all these concepts.
- The basic element-wise operation is bandwidth-limited which
means that the CPU is spending most of its time to memory
reads and writes! So you don't expect large speedups.
- Compare the manual optimization with Od. Is the optimization
flag O2? Then the compiler might have optimized better than
you manually!
- Together with the code I provided a Visual Studio tips file.
Read it.
- Hand in Visual Studio code with only the
following:
- see also "Visual Studio tips - copy.txt" in main folder
of AlgorithmOptimization code
- your projects, not my projects
- solution file for the projects
- project files: *.vcxproj files
- source files: .cpp and .h, opencl files
- the include folders
- delete all executables and intermediate files (a lot!!)
- you can do a clean in Visual Studio, but this is
unsufficient, a lot of files remain
- make sure it compiles out of the box, test it!
- Hand in a report (20% of marks for the course) containing:
- CPU info [extra: test on 2/3 different processors]
- performance results (generated table) for all optimizations
- shortly discuss results, analyze and take conclusions
- For sequential code answer the following questions:
- How much can the compiler optimize the code? Are the loops
unrolled? The instructions vectorized?
- Which pragmas help the compiler in further optimizing the
code?
- Can yo reach the same speed with manual optimization and
flag Od?
- For multi-threaded code, answer the following questions (no
need to compare with Od)
- Does multi-threading further speedup the code (O2-flag)?
- Does automatic parallelization (pragma) works?
- try to estimate the maximal GFlops and maximum GB
from your results
- visual studio code (zipped). Remove object and exe-files
(and all other intermediate files). Use Build ->
clean for instance and remove the .vs folder manually.
Minimally, we need source files, and solution (.sln) and
project file (.vcxproj).
- Bonus points: check and discuss generated assembler code in
godbolt.org/
Exercises on multithreading and MPI All solutions
All solutions
(given after the exercise sessions; remind me) - note: to have
speedup for the Counting3s, compile without optimizations (Od)
1. Implement a multithreaded fibonacci
algorithm [project Fibonacci].
- Base the calculations on the recursive definition. This
is of course not the most intelligent solution, actually
terribly dumb. Let's assume
that it is the only way of calculating fibonacci.
Since it generates a lot of computations, it is good for
obtaining speedup when run in parallel!
- Fibonacci (n) = Fibonacci (n-1) + Fibonacci (n-1) if
n > 2
- Fibonacci (n) = 1 if n = 1 or n = 2
- Fibonacci (n) = 0 if n < 1
- There are several ways to decompose the problem. Try to find
a solution for which you can parameterize the number of
threads.
- Study the performance in function of the number of
threads.
- Extra question: Try to get an ideal speedup (= number
of cores).
- If this ideal is not met, try to find an explanation!
- Advanced questions:
Is it a load-balanced solution? Count the number of threads.
Count the number of work of each thread or time the
computation time of each thread.
- Extra question: Use the task parallelism
capacities of OpenMP: see PPCP pages 209-212.
2. Implement a multithreaded
matrix multiplication [project MxM].
- Try to make a solution in which you can set the number of
threads.
- What speedup do you obtain?
- What is the maximal number ot threads?
- How does the speedup evolves with increasing number of
threads? And with increasing matrix size?
- Try to estimate the thread overhead by testing solutions
with different number of threads.
3. Test the the performance of various Count3s
implementations [project Counting3s].
- The given first parallelized solution is wrong. Why?
- Explore different solutions (their correctness and their
performance).
4. Check Invariance-breaking (See
slides on MT: first example of thread safety) [project
InvariantBreaking].
- In the threads, do a
lot of updates of the upper and lower values to generate race
conditions. Check the invariant each time, so that you see when
it is broken.
- Don't put extra print statements in the threads. They will
considerably slow down the threads and lower the chance of a
race condition.
- Consider using a lock_guard,
which is a construct built on top of locks to prevent you
forgetting unlocks.
- Why don't you get a thread-safe solution with volatile? Which
solution gives a correct program?
- Test it with at least 10.000.000 iterations.
- Can something go wrong with CheckInvariant?
5. Implement a Barrier [project
Barrier].
- Implement the barrier function such that all threads wait for
the last thread to finish.
6. Implement a multithreaded solution for the
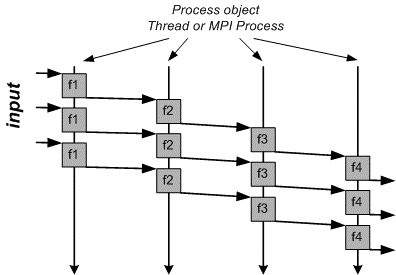
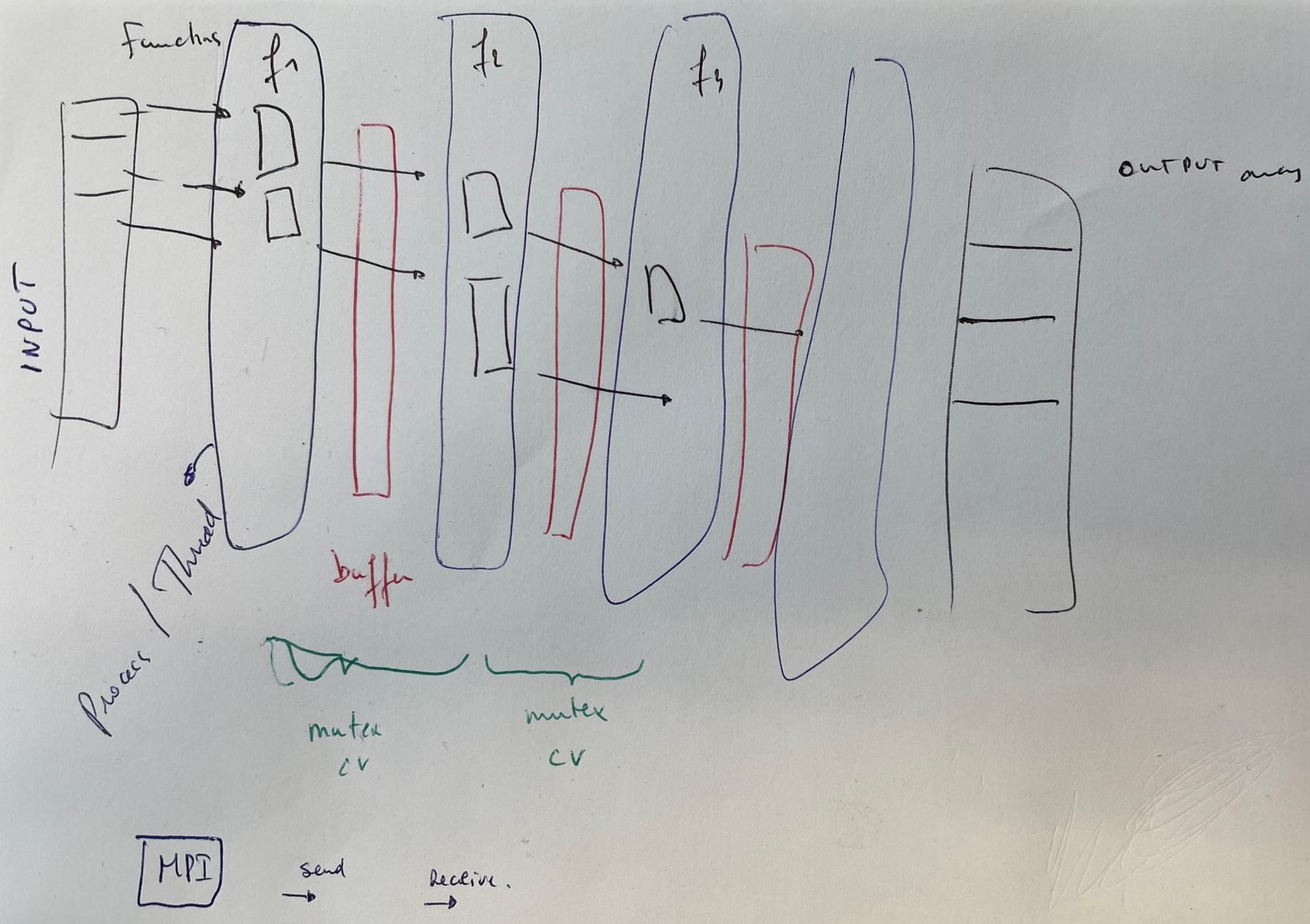
pipeline algorithm. [project Pipeline].
- Scheme
- Parallelize the pipeline by keeping each Function object on
one thread (or process in case of MPI). The data will migrate
from one thread to the other.
- Scheme of
parallelization
- There are different possible solutions!
- [Jan: see hackaton solutions of Peter, Cedric, Milan
(ExamenMT.cpp)] or via barrier
7. Implement an MPI solution for the previous
pipeline algorithm. [create project PipelineWithMPI].
- Which parallel solutions (MT or MPI) is easier to implement?
- [Jan: see solution of Victor]
8. Test the different MPI point-to-point communication
protocols [project QuicksortMPI].
- Which is most efficient when?
- Back to the
top -
{kind=link}
{kind=link}