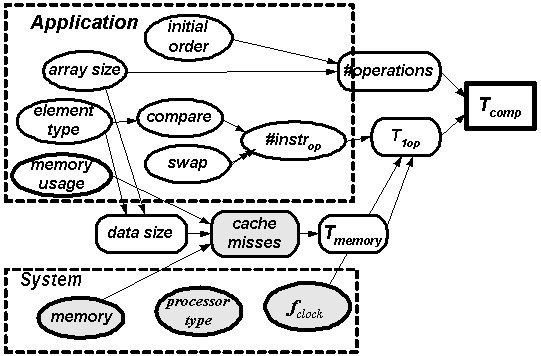
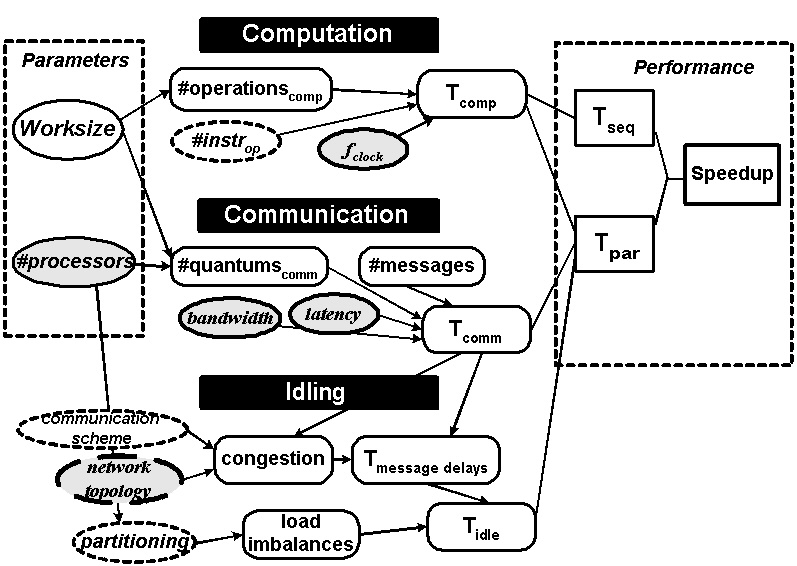
Introduction - Causal Structure Learning - Philosophy, MDL & Assumptions
This
research
investigates how causal structure learning algorithms can
aid the
performance analysis of (parallel) programs.
More information & publications: Jan Lemeire (jan.lemeire@vub.ac.be) & Stijn Meganck
 Our causal
learning module Experimental
Setup Research
results,
explained with examples Information
analysis
module Kernel
density
estimation (KDE) module Interactive
tutorial
on causality, information and KDE
Our causal
learning module Experimental
Setup Research
results,
explained with examples Information
analysis
module Kernel
density
estimation (KDE) module Interactive
tutorial
on causality, information and KDE