MPI for C/C++
MPI stands for Message Passing
Interface,
it is the standard programming tool for message-passing programs. It
replaces
the good-old pvm.
We use the LAM/MPI implementation. This implementation seems not to
exist
for Windows. But since MPI is a standard inferface, any MPI program can
be recompiled with a different implementation.
See also: MPI Troubleshooting
 Online documentation
Online documentation
Compile your MPI-program
Compile with mpicc for C
programs
and mpic++ for C++, a wrapper
compiler
that adds the correct compiler & linker flags.
Run & debug your parallel program (see LAM/MPI user guide)
On
our LINUX system: Computers
you can use to run in parallel: parallel1,
parallel2 ... parallel7 (Some might not be running)
- First start mpi:
- start it with lamboot
<options> <hostfile>
- the -v option
(verbose)
is to show some extra messages
- you should give a hostfile
with all computers you want to be available for MPI
- use the lamnodes command
to see how many computers are in the LAM universe
- To start your parallel program:
- mpirun C
<executablename> <arguments>
- the C option means to launch one copy of the executable on
every
computer of the LAM universe
- mpirun -np 4 <executablename> <arguments>
- create 4 processes that are distributed evenly among the
available processors
- use mpitask to
see
all mpi programs running
- use lamclean to
stop
all running processes
- To debug a process or
redirect the output of the slaves: use a script
However, this does not work with VNC...
Terminate:
Don't
forget to halt mpi with the lamhalt
command when you
stopped
experimenting!!
Otherwise your mpi-processes keep on running! Also when you log out!
Cluster
ONLY ACCESSIBLE FROM OUR
LINUX SYSTEM
Do your final experiments (performance
measurements) on the cluster
(ask
first for permission to your assistent):
- our 8 dedicated cluster computers (Intel Pentium II 333MHz,
256MB
RAM) are called node01,
... and node08
- To run your parallel program:
Program Example
Download the code
Download the code all at once with this
compressed archive file:
mpiExample.tgz, extract the
files
in a new directory with command:
tar -zxf mpiExample.tgz
The files:
Run the program
- start MPI with lamboot
hostfile.txt
- create the makefile starting from the project file problem.pro
with qmake and compile it
- run your parallel program
- try to understand the program (documentation)
- Study it:
- View all program arguments: mpiex-h
- Increase the array size: mpirun
C mpiex -s 1000
- Control the number of processes: mpirun -np 4 mpiex -s 30
- Run master and/or slave in debug mode with script: mpirun C mpistart.csh mpiex
Exercises
- Do a small performance analysis:
- When do we have a speedup? For what array sizes and how many
slaves?
- What deteriorates the performance?
- Count the number of computations that each slave performs
(automatically).
- Also measure the computation time of each slave
- Optimize the communication by choosing a more appropriate MPI
communication operation, check whether it improves performance.
- Does non-blocking
sending improves the speedup?
- Use collective operations: Reduce, Scatter.
- Use a pack/unpack for sending the array size and array all in
one message
- Note: the array size could be calculated by each slave
itself
when the global array size would be passed to
ApplyPredicateOnArray_Slave.
- Change the task of the parallel program to Is8398551DivisibleByValue. How
is the performance now? why?
- Measure the communication time and the ratio communication
versus
computation
- Solve the load imbalance problem!
- eg: divide the given range in a great number (> p) of
subranges.
Send the first subranges to the slaves, send the next subranges
whenever a
slave has finished with its subrange.
Program Example with automatic EPPA
instrumentation
Download the code
Download the code all at once with this
compressed archive file:
mpiEPPAExample.tgz,
extract the
files
in a new directory with command:
tar -zxf mpiEPPAExample.tgz
The program is similar to the previous one, only:
- standardlib is
ommited, since it is integrated in the par library.
- We check the status of the message to retrieve the array size
(functions send_array
& receive_array).
- Error handling is changed with MPI_Comm_set_errhandler (after
the MPI_Init), now the
MPI will simply return when an error occurs and the return code should
be checked for errors. We do thsi with CheckForMpiError to print more
detailed information about the error.
- Additional MPI_Pcontrol
statements to provide extra information to EPPA (but this is not really
necessary).
- The program is linked with the par library (this automatically
instruments your MPI program) & mysql library (to write your
results to our MYSQL database)
- If necessary, create the PARDIR environment variable that
points to the directory of the par
library.
- The number of basic operations (variable gTaskNbrCalculations) is
counted in the functions of the tasks.cc
file, this is passed to EPPA.
On our LINUX system
EPPA is installed under the
$PARDIR
directory, which is in your path, so just type
EPPA to run it. It shows all of
your experiments.
With
ViewExp <experiment
ID> you can visualize one experiment. With
ViewExp your latest experiment
is shown.
On another
system (with QT, mpi and mysql), EPPA can be installed
See
EPPA User Documentation
More examples
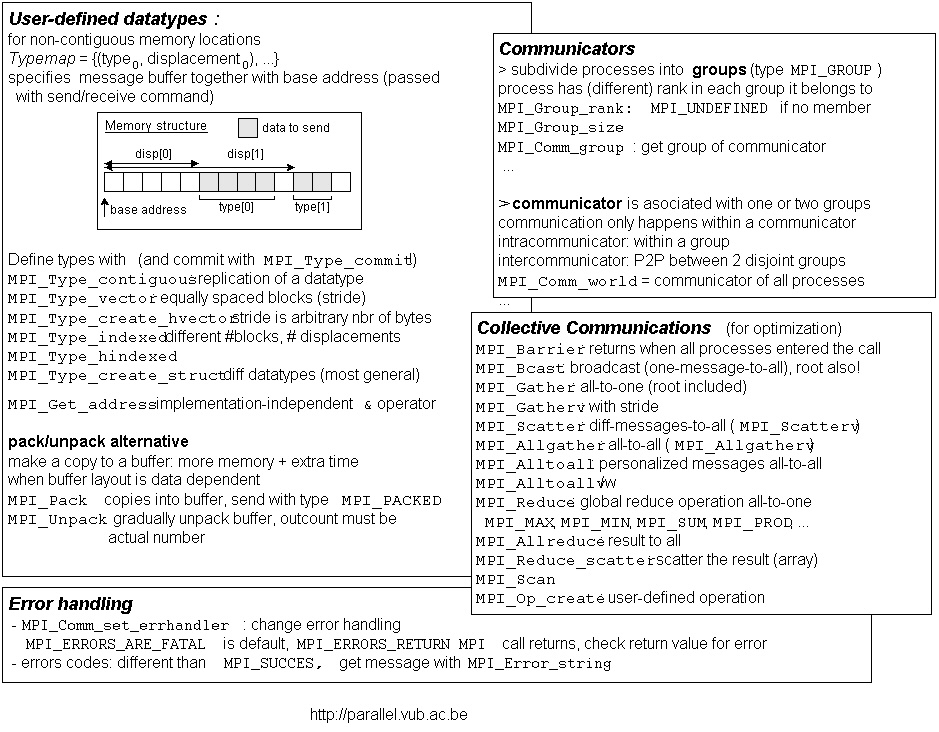
- Examples on sending more complex datastructures: source file, project file
- create with qmake
&& make
- run with mpirun -np 2
mpiTypeTest -t <testnumber>, where testnumber is a number
from 0 until 7
 page!!
page!!{kind=link}
{kind=link}
{kind=link}