Parallellisatie van POVRay
Inleiding
Iedereen maakt het wel eens mee, soms meer dan hem lief is: dat je moet wachten op je PC omdat de processor bezig is met één of andere intensieve berekening. Hoewel de huidige generatie microprocessoren zeer krachtig is, en meer dan voldoende snel voor de software die we het merendeel van de tijd gebruiken -office toepassingen, tekenprogramma?s, spelletjes en internet software- zijn er eveneens talloze gebieden waar men nood heeft aan een enorme rekenkracht: bij het uitrekenen van complexe wiskundige problemen, simuleren van allerhande klimatologische verschijnselen, ontcijferen van coderingsalgoritmen. Zelfs bij het ?simpele? renderen van een 3D tekening moet je vaak uren, tot zelfs dagen, wachten alvorens het resultaat op je scherm verschijnt.
Omdat men wegens fysische beperkingen de snelheid van processoren niet oneindig kan opdrijven, moeten er andere oplossingen gezocht worden. Zo zijn er massieve multiprocessoren: speciaal ontworpen machines met duizenden processoren die specifiek voor 1 (of enkele) taken gebouwd worden. Nadeel is de enorm hoge kostprijs, veel hoger dan wanneer men evenveel stand-alone machines zou gebruiken. Veel economischer is om een aantal door een netwerk verbonden machines te laten samenwerken om zo sneller tot resultaten te komen. Het is hier dat zich dit werkcollege situeert: we gaan trachten een freeware raytracer, POVRay (Persistence of Vision Raytracer), te parallelliseren met behulp van PVM (Parallel Virtual Machine). Dit is een programma dat bestaat voor verschillende besturingssystemen (Windows, Linux, talloze Unix varianten?) en dat een aantal functies bevat die toelaten om vrij gemakkelijk een programma aan te passen voor parallelle verwerking.
Over POVRay
Wat is POVRay? Zoals reeds vermeld is het een ray-tracing programma dat zeer realistische, drie-dimensionale beelden genereert uitgaande van een tekstbestand (de source- of scene description file). Dit bestand bevat de informatie betreffende alle objecten en lichtbronnen binnen een scene, deze worden bekeken vanuit het standpunt van een camera die eveneens in deze file beschreven staat.
De gebruikte techniek, ray-tracing, gaat een afbeelding visualiseren door te berekenen welke weg de lichtstralen afleggen; in werkelijkheid worden deze uitgezonden door een lichtbron en dan weerkaatst of geabsorbeerd al naargelang het object waarop ze botsen. Maar ray-tracing gaat omgekeerd te werk: vertrekkende vanuit de lens van de camera worden lichtstralen berekend naar de omgeving toe. Zo vermijdt men het berekenen van stralen die toch niet in de camera invallen en dus van geen belang zijn.
Het grote voordeel van de ray-tracing techniek is het uitzonderlijke realisme dat bereikt wordt: schaduwen, weerkaatsingen, perspectief etc. worden allemaal zeer natuurgetrouw weergegeven. Maar er is ook een schaduwzijde: het is een traag proces, dat letterlijk miljarden berekeningen vergt om van elke pixel te bepalen welke kleur hij bezit. Men ziet dus al snel in dat door een geparallelliseerde versie te gebruiken, men de rekentijd significant kan terugbrengen? en er geldt immers steeds ?time is money?.
Het parallelliseren
In eerste instantie hebben we geprobeerd om zelf POVRay te parallellizeren.
Vertrekkende van de originele source code creëerden we 2 afzonderlijke programma?s: een master en een slave versie. Ons idee was van de tekening lijn per lijn door de slaves te laten renderen terwijl de master bijhoudt wat er waar gedaan wordt en tevens de gerenderde lijnen bij elkaar voegt tot één figuur. De master vervult aldus de volgende taken:
- start de slaves op
- geeft hen deze opties door (ondermeer de locatie v.d. source file)
- zegt elke slave welke lijn er gerenderd dient te worden
- ontvangt elke lijn terug van de slaves samen met een index, om de juiste volgorde te onthouden
- ordent de lijnen en voegt ze samen tot een tekening
- stopt de slaves wanneer alles gedaan is
- parsen de source file
- wachten op een lijn nr. van de master en renderen deze
- verwittigen de master wanneer dit klaar is
- sturen de lijn terug naar de master
- renderen evt. een volgende lijn
Zoals dit ook in de cursus Geavanceerde Computerachitectuur beschreven staat, vonden we dat het renderen van een afbeelding grosso modo uit 2 onderdelen bestaat: allereerst een sequentieel deel dat de initialisatie van het programma en de verscheidene variabelen en het parsen van de source file behelst; anderzijds het eigenlijke renderen zelf. In de parallelle versie is het dit tweede onderdeel dat tegelijkertijd door meerdere machines wordt uitgevoerd, het sequentiële deel loopt quasi ongewijzigd op een host die men de master noemt en die als taak heeft de verscheidene slaves steeds weer van informatie te voorzien en omgekeerd ook berekende stukken in ontvangst te nemen en deze in elkaar te passen tot de uiteindelijke output file. Wij kozen ervoor om het master- en het slave-proces volledig gescheiden te houden en de master dus niet te laten meerenderen, zodat deze zich enkel met de controle dient bezig te houden en we (hopelijk) meer nauwkeurige metingen bekomen.
(Voor alle volledigheid de werkwijze van PVMPOV: de initialisatie-procedure loopt enkel op de master, deze maakt ook de slaves aan en voorziet ze van eerste gegevens. Vervolgens parsen alle slaves eenmaal de sourcefile en beginnen daarna te renderen. Al naargelang van de opgegeven blokgrootte (het kleinste stuk dat aan een slave wordt toegewezen) verdeelt de master de totale oppervlakte van de tekening in meer of minder blokken die dynamisch en zeer intelligent naar de slaves worden doorgespeeld: zo zal een slave die halfweg een blok is, reeds een volgende blok aanvragen om zo te vermijden dat bij zware netwerkbelasting de processor zonder werk komt te zitten omdat gegevens niet snel genoeg arriveren. Tevens houdt de master bij hoelang elke slave aan een blok bezig is; indien 1 slave beduidend meer tijd nodig heeft dan de anderen, dan wordt het betreffende blok reassigned aan een hopelijk snellere host.)
Enkele tests door ons uitgevoerd, bewijzen de juistheid van de aanpak van PVMPOV: we maten met de originele POVRay voor een aantal verschillende source files, de duur van zowel het sequentiële als van het parallelliseerbare gedeelte. Voor het eerste stuk bekwamen we nooit tijden boven de 4 seconden, zelfs indien de source files meerdere megabytes groot waren. Het renderen daarentegen duurde veel langer: dikwijls in de orde van 100 seconden, maar met uitschieters tot wel 13.000 seconden! We kunnen dus rustig stellen dat het sequentiële gedeelte verwaarloosbaar klein is tov. het parallelliseerbare, en het is net deze eigenschap waardoor POVRay zich zozeer leent tot parallelliseren.
Enkel bij de tekening r-wing-x.pov is de parsetijd van dezelfde grootte orde als de rendertijd, dit wegens de grote simpliciteit van de afbeelding. Bij de 4 andere figuren is deze te verwaarlozen.
POVRay zelf telt talloze opties die we kunnen meegeven om aldus de kwaliteit van de bekomen tekening te beïnvloeden. Enkele voorbeelden zijn het toepassen van anti-aliasing, het weergeven van een snelle preview, het uitvoeren van radiosity berekeningen (dit berekent diffuse inter-reflectie voor een nog betere kwaliteit) enz. Tot onze spijt hebben we moeten vaststellen dat het merendeel hiervan (nog) niet geïmplementeerd is in PVMPOV, wat jammer is omdat zulke berekeningen enkel het parallelle stuk beinvloeden en dus een prachtig instrument zijn om na te gaan wat er gebeurt als er voor eenzelfde inputfile plots veel meer berekeningen nodig zijn. De auteurs van PVMPOV vergaten bovendien om dit expliciet te vermelden zodat we dit slechts al doende te weten zijn gekomen.
Anderzijds zijn er ook enkele parameters die we wel
kunnen specifiëren: je kan de blokgrootte kiezen, het aantal te spawnen
tasks per host, op welke hosts deze tasks moeten draaien en de prioriteit
van het proces.
Onze tests
Deze hebben we steeds uitgevoerd op 5 verschillende figuren, om een verband te kunnen leggen tussen opbouw van de tekening en efficiëntie van de parallellisatie. We gebruikten 1 relatief eenvoudige en snel te renderen tekening, doch met een relatief hogere parse tijd: 3 sec (r-wing-x.pov). 2 andere figuren zijn tamelijk homogeen qua complexiteit, maar nog steeds eenvoudig om te berekenen en dus met een een relatief lage rendertijd (foucpend.pov en fryanegg.pov). Tenslotte een iets langzamere en tevens zeer heterogene figuur (pcktwtch.pov) en een homogene, zeer complexe met een lange rendertijd (iaclock.pov).
De testen die we hebben uitgevoerd kunnen we rangschikken in 3 categorieën. Ten eerste zijn we nagegaan of we de Andahl curve terugvonden. Dit hebben we gedaan door eerst crunchen toe te voegen met telkens 1 task per crunch. Het feit dat we slechts 8 crunchen hadden hebben we geprobeerd op te vangen door meerdere tasks per crunch te laten draaien (2® 8). Maar dit vervalst eveneens de metingen aangezien we nu terug meer een sequentieel probleem bekomen: de processor kan slechts 1 task tegelijk berekenen en de tasks moeten dus wachten op elkaar. We hebben dan gekeken of de curven een verschillende vorm hadden voor een andere grootte van het blokje dat de verschillende crunchen moeten renderen.
Ten tweede hebben we de invloed van de resolutie op de speed up bekeken. Een hogere resolutie impliceert een hoger aantal pixels en dus een hoger aantal berekeningen.
Uiteindelijk hebben we geprobeerd een verband te
leggen tussen de blok-grootte enerzijds en de resolutie en complexiteit
van een figuur anderzijds.
Noot
Wanneer we het in het verdere verloop van dit
verslag hebben over ?sequentiële? en ?parallelle? tijden, dan bedoelen
we respectievelijk de tijd nodig voor de originele versie van POVRay en
voor PVMPOV om de tekeningen volledig te berekenen. Deze tijd omvat zowel
de parse tijd (sequentieel) als de rendertijd (parallel).
Theoretische achtergrond
Andahl?s wet
Volgens Andahl kan de uitvoeringstijd van een algoritme (of programma) opgesplitst worden in 2 delen: de sequentiële en de parallelle rekentijd. De sequentiële rekentijd omvat dit deel van het probleem dat niet kan geparallelliseerd worden: omdat er gegevens nodig zijn die net tevoren pas berekend werden, omdat het gaat om initialisatie van variabelen etc? Dit gedeelte moet steeds, ook wanneer we het probleem gaan parallelliseren, door 1 host uitgevoerd worden en hier kan men dan ook geen tijdswinst boeken. Dit is wel het geval bij het parallelle deel, wanneer we dit door N hosts laten uitvoeren ipv. door 1, zal de tijd ervoor nodig met een faktor N afnemen.
Stellen we T1 de sequentiële en TN de parallelle rekentijd; en a de sequentiële fractie in T1, dan kunnen we dit uitschrijven als:
Zo bekomen we voor de speedup:
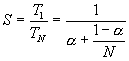
hetgeen voor N groot nadert tot 1/a .
De efficiëntie wordt gegeven door en benaderd (voor grote N) door:
![]()
We zien dus dat we, om een goed mogelijk parallelliseerbaar
programma te bekomen, best de sequentiële fractie zo klein mogelijk
maken. Dit is niet steeds mogelijk en sterk afhankelijk van het te bestuderen
probleem, men kan bvb. moeten wachten op user input, op resources die niet
vrij zijn, bepaalde algoritmen kunnen gewoonweg niet parallel uitgevoerd
worden? Zoals reeds gezegd is dit bij POVRay niet het geval, en dit is
net wat het zo?n geschikt testonderwerp maakt.
Invloed van de communicatie
Parallellisatie van een probleem brengt onherroepelijk communicatie met zich mee: uitwisseling van gegevens tussen master en slaves (soms ook tussen slaves onderling) en controlecommandos van de master aan de slaves. Nu is het zo dat wanneer we zeer veel hosts beschouwen, de bandbreedte van het netwerk ontoereikend wordt voor de hoeveelheid informatie die moet worden uitgewisseld. Vanaf dit punt zal het toevoegen van meer processoren niet alleen nutteloos blijken, het zal zelfs contraproductief zijn: meer processoren betekent nog meer verzadiging van het netwerk zodanig dat de processoren moeten wachten tot er data beschikbaar is.
We drukken deze communicatiebottleneck als volgt uit:
![]()
Hierbij is de overhead lineair evenredig met het aantal hosts:
![]()
We bekomen voor de speedup:
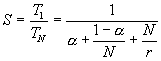
met hierbij r = Ts/TCOMM1![]() dus
de verhouding tussen de sequentiele rekentijd en de communicatie-overhead
bij implementatie op 1 processor.
dus
de verhouding tussen de sequentiele rekentijd en de communicatie-overhead
bij implementatie op 1 processor.
Deze overhead vinden we als:
![]()
dus in functie van latency, bandwidth en datasize van het netwerk.
We onderscheiden 3 delen van de curve:
als S » 1/a dan is d S/d N » 0
als S »
r/N dan is d S/d
N » -r/p2
< 0
reduceer a
- algoritmisch: door optimalisatie
- architecturaal: door bvb. een dedicated netwerk te gebruiken
- los meer dan 1 probleem tegelijkertijd op, dwz.
optimaliseer de throughput van de machine
- kleine TCOMM1: maximaliseer de bandwidth
- kleine L: minimaliseer de latency
- minimaliseer de datasize
Bespreking van de metingen
Test 1 ? de Andahl curve
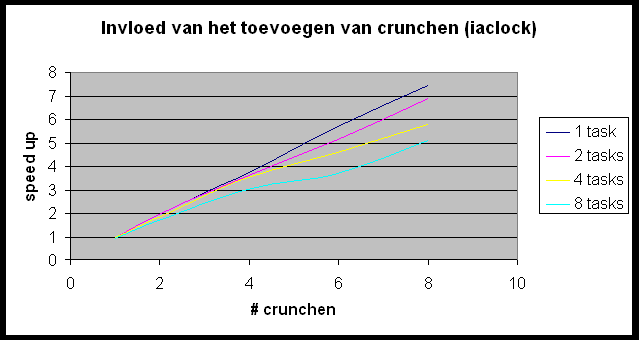
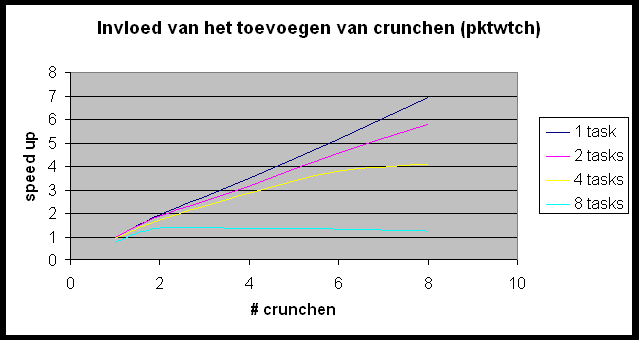
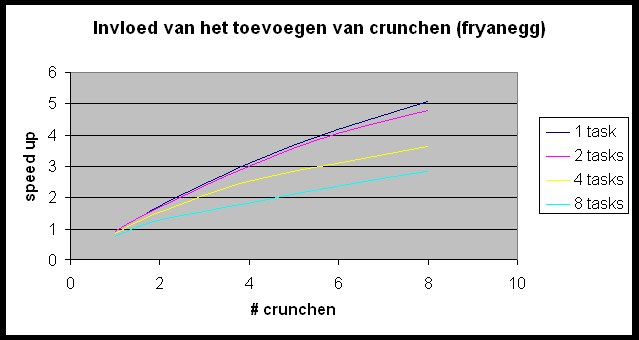
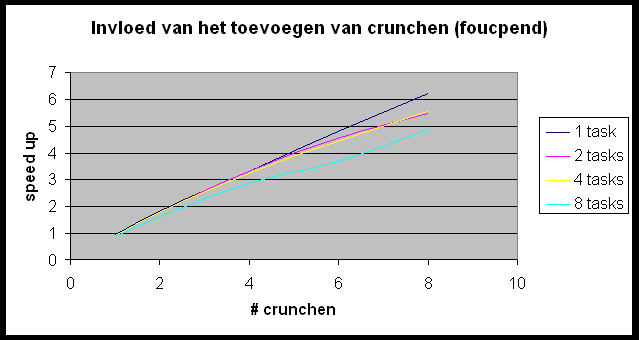
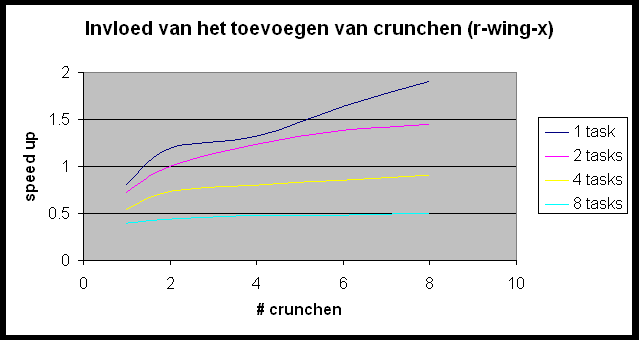
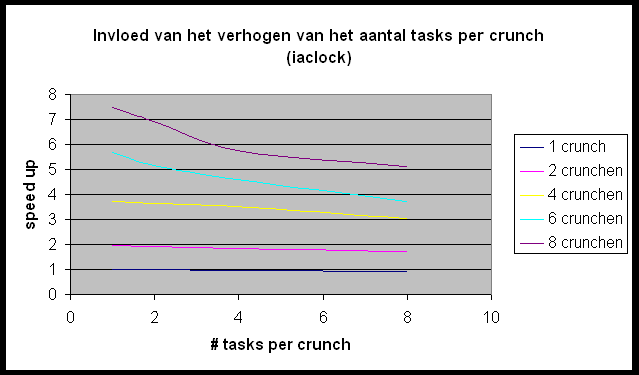
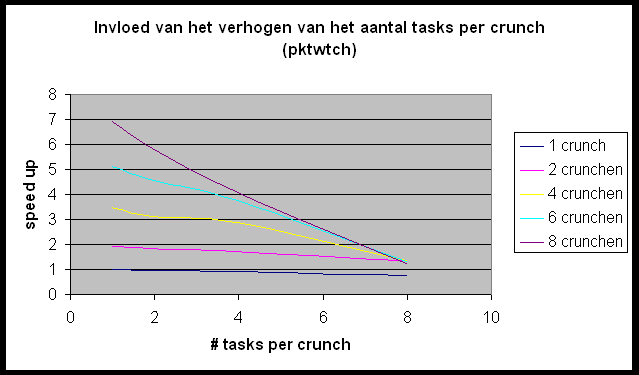
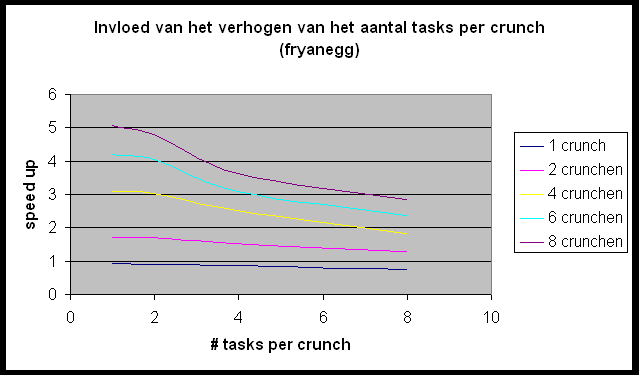
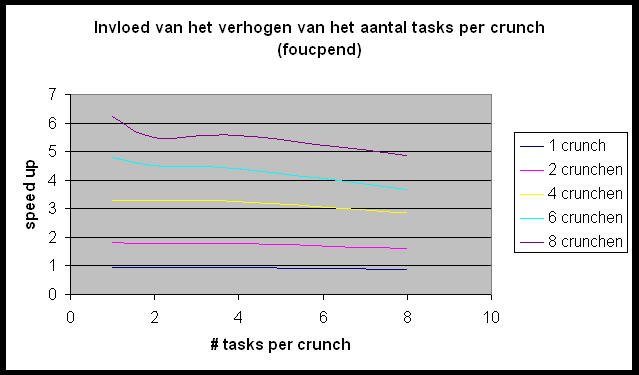
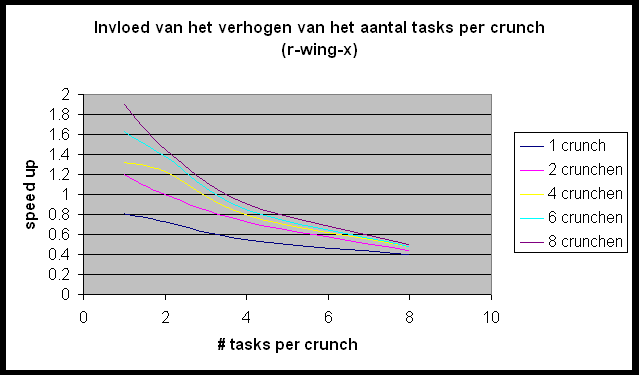
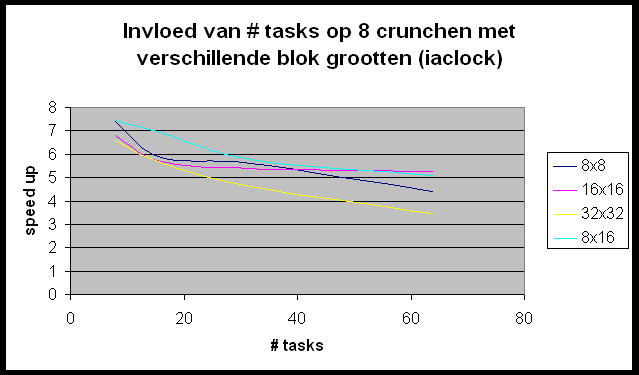
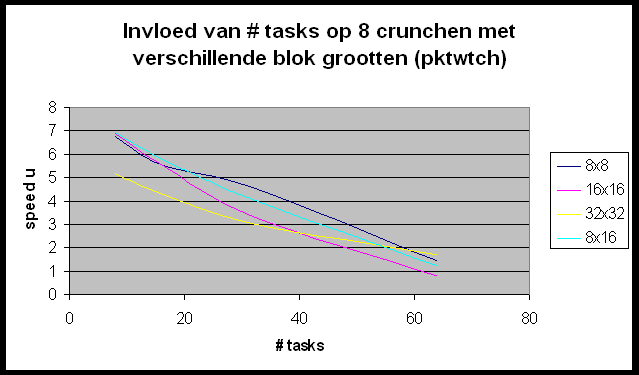
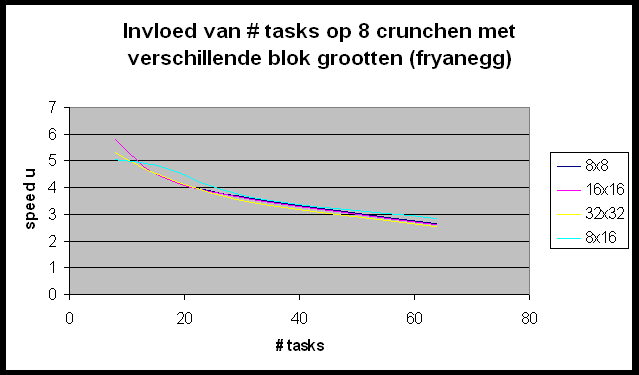
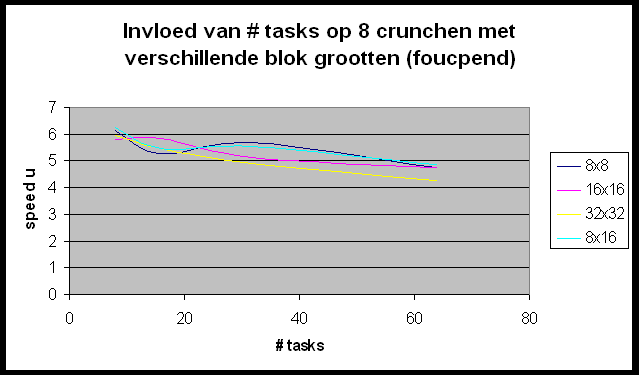
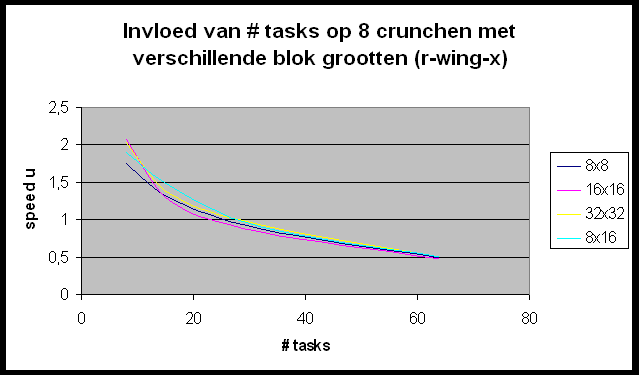
We willen de Andahl curve bekomen maar we bemerken dat we ons nagenoeg altijd in het eerste, lineair stijgende deel van de grafiek bevinden. Slechts in enkele gevallen (r-wing-x met 8 tasks per host en pcktwtch met 4 en 8 tasks per host) krijgen we het vlakke en zelfs een beetje het dalende gedeelte van de grafiek te zien.
In het geval van pcktwtch kunnen we een poging doen om uit de grafiek a te berekenen: in het lineaire deel van de curve is S » 1.5; N is groot dus is a » 0.66 (1/S). Nu berekenen we a op de correcte manier (pcktwtch; 8 hosts; 1task/host):
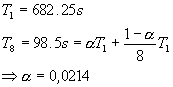
Het enorme verschil wijst er nog maar eens op dat het uitvoeren van meerdere tasks per host wel degelijk een zeer grote impact heeft op de metingen.
In het algemeen ontstaat er dus onvoldoende netwerkverkeer opdat de performantie eronder zou lijden. De reden hiervoor is dat PVMPOV een zeer efficiënt programma is, het is geoptimaliseerd om niet zonder data te vallen en om network congestion te vermijden. We hebben de code van PVMPOV grondig doorgenomen en zijn tot de volgende vaststellingen gekomen:
de slaves vragen aan de master reeds een nieuw te berekenen blok alvorens ze hun huidige berekeningen hebben beëindigd. Dit om te voorkomen dat, wanneer het blok traag binnenkomt wegens veel netwerkverkeer, de host zonder data zou vallen en dus idle komt te staan.
de blokken worden niet in hun geheel, maar in 4 stukken berekend en ook doorgestuurd: dit voorkomt al te bursty netwerktraffic en onbelaste processoren. Dit laatste wordt eveneens tegengegaan door, wanneer een task abnormaal lang over een blok doet, de blok gerealloceerd wordt aan een andere host waarvan PVMPOV vermoed dat hij sneller is. In sommige gevallen echter werkt dit in ons nadeel: bvb. de crunches zijn elk even krachtig en wanneer we zeer heterogene tekeningen qua complexiteit renderen, is het soms zo dat een moeilijk blok dat bijna klaar is, wordt afgebroken en op een andere machine gestart wat natuurlijk vertragingen induceert.
Het niet bekomen van de Andahl curve is ons insziens vooral te wijten aan het feit dat er op voorhand blokken worden aangevraagd: aldus is de kans dat de tasks op data moeten wachten en dus werkelijk geplaagd worden met een communicatiebottleneck, zeer klein: tegen de tijd dat de overblijvende stukken blok gerenderd zijn is de gevraagde informatie reeds gearriveerd.
Ten slotte is het te vermelden dat met slechts 8 machines het moeilijk is om communicatieoverhead te meten aangezien door de hierboven vernoemde optimalizaties, PVMPOV de data-uitwisseling reeds sterk beperkt en spreidt in de tijd. Wij hebben getracht dit op te lossen door meerdere tasks per machine, maar dit vervalst eveneens de metingen aangezien we nu terug meer een sequentieel probleem bekomen: de processor kan slechts 1 task tegelijk bedienen en de tasks moeten dus wachten op elkaar.
Dit is duidelijk te zien op de grafiek die de invloed van het verhogen van het aantal tasks per crunch weergeeft. Bij het toevoegen van een task per crunch stijgt de communicatie zonder er eigenlijk een processor bijkomt. Dit impliceert dat de positieve effecten van meer tasks (meer parallel werkende processors) hier niet geldt, maar de negatieve invloeden (meer communicatie) wel een invloed heeft.
Toch geeft de meting met 8 tasks per crunch een mooie benadering van
de Andahl Curve. Dit is omdat Andahl juist zegt dat de communicatie gaat
primeren op het toevoegen van het aantal processors (hier tasks). Als we
de blokgrootte van de door te zenden blokjes variëren dan heeft dit
bijna geen invloed op de vorm van de grafiek.
Test 2 ? invloed van de resolutie op de speedup
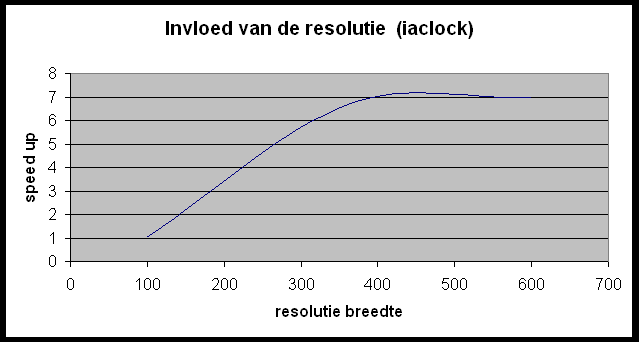
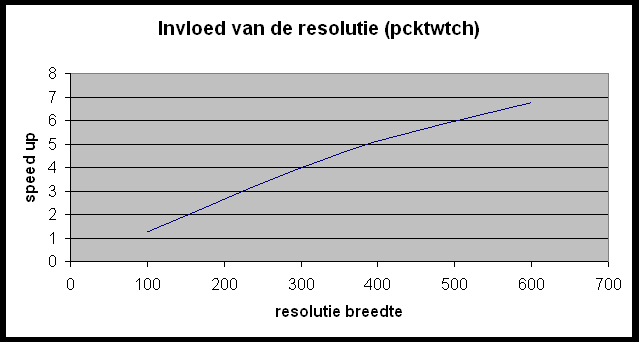
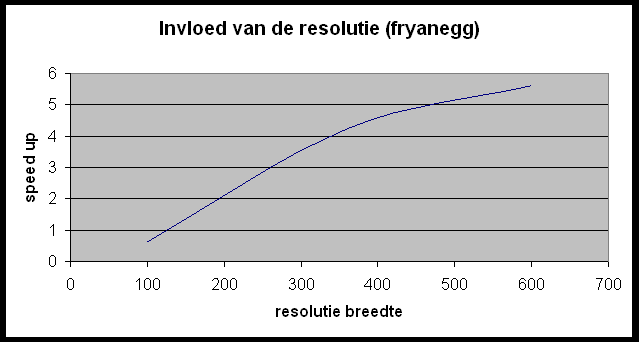
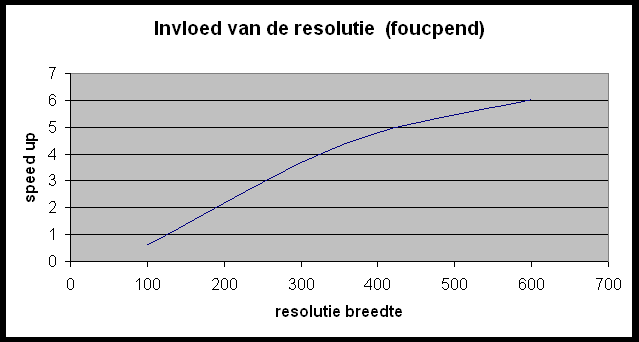
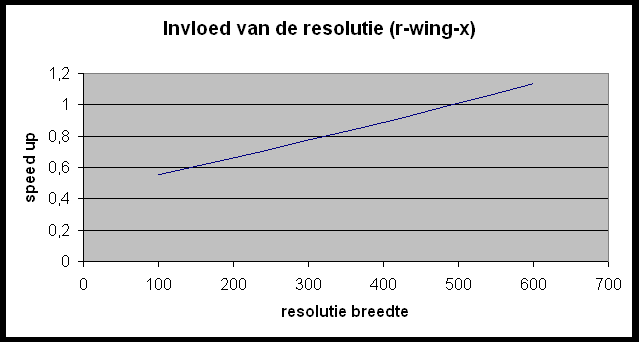
Wat kunnen we hieruit concluderen?
Test 3 ? invloed van de blokgrootte
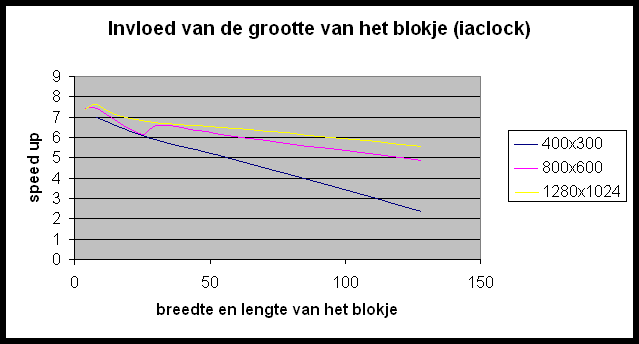
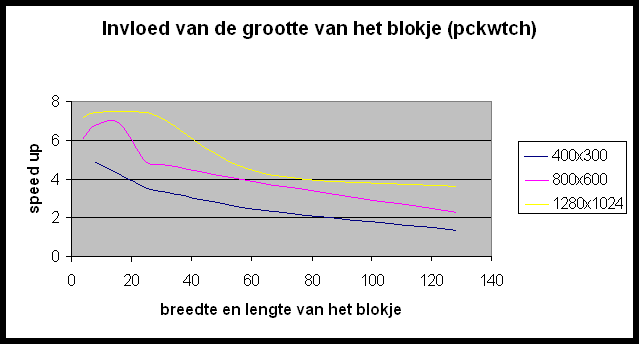
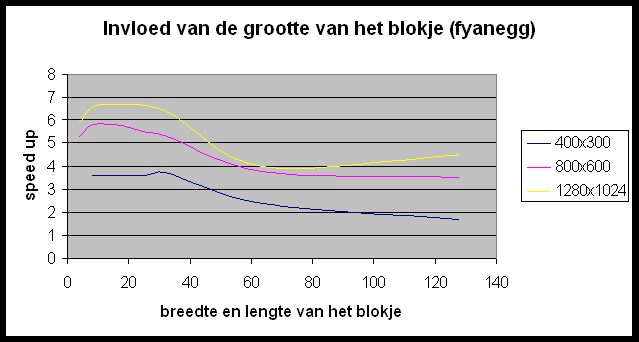
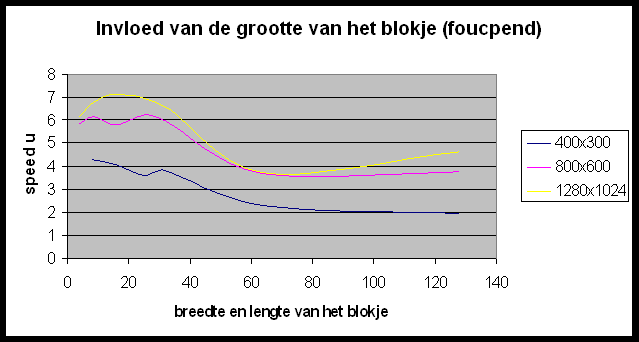
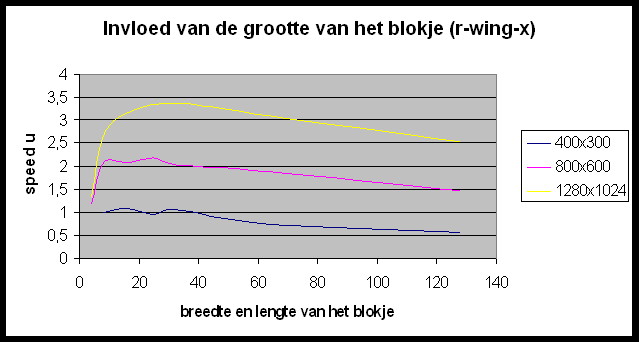
In POVRay is het mogelijk de grootte te specifiëren van de blokken die naar elke slave gestuurd worden om gerenderd te worden. We gaan eens een kijkje nemen of we hier geen performantiewinst kunnen boeken door een ideale blokgrootte te selecteren. De resultaten die we hier bekomen zijn ietwat merkwaardig. Wat bemerken we?
Hoe verklaren we dit ?
Besluiten
- POVRay leent zich zeer goed tot parallellisatie vanwege de kleine sequentiële fractie in de totale rekentijd
- Om tot de Andahl curve te komen beschikken we over te weinig hosts, dit omdat PVMPOV zeer efficiënt omgaat met de beschikbare bandbreedte. Simuleren van een groter aantal hosts (dmv. meerdere tasks per host) geeft ons wel een idee van de curve, maar leidt tot verkeerde metingen.
- Des te groter de tekening (in casu resolutie) of hoe meer opties men gebruikt (zoals anti-aliasing), des te langer duurt het parallelle deel van de berekeningen en dus hoe groter de speedup.
- Het belangrijkste instrument dat we hebben om de performantie te optimaliseren is de grootte van de te renderen blokken; de optimale waarde hiervoor is afhankelijk van zowel grootte als opbouw van de beschouwde figuur (homogeen « heterogeen).
- Wanneer we dus een snelle parallelle machine willen
bouwen, speciaal voor POVRay, dan is het aangewezen van vooral veel
machines te voorzien en niet zozeer een snel interconnectienetwerk, om
de grootste snelheidswinst te boeken.