Relational Database tutorial
The experiments database
1. data - 2.
ERD - 3. creation - 4.
queries - 5. C - 6. data
analysis
Datatabase are used to store data in a structured way. Let's
explain the basics with a small example.
To execute this example, configure
your account first.
1. The Data
Assume I want to store the results of experiments performed at the lab.
I group the data in 4 tables. Each row contains the information
about 1 specific item or entity, the columns represent
the information elements.
experiments
| ID |
name |
creation |
who |
p |
comment |
| 1 |
my first parallel program |
22/2/2002 |
jan |
4 |
just a test |
| 2 |
parallel genetic algorithm |
22/3/2002 |
jan |
8 |
|
| 3 |
parallel curve measurements |
25/3/2002 |
erik |
8 |
speedup curve |
p is the number of processors of the parallel experiment. The who column
is a person selected from the users table.
users
| name |
function |
| jan |
assistant |
| johan |
assistant |
| erik |
professor |
| andy |
student |
variables
| name |
isParallel |
explanation |
| Ts |
FALSE |
sequential processing time |
| Tp |
TRUE |
parallel processing time |
| Tpart |
TRUE |
partitioning time |
| Tsync |
TRUE |
synchronisation time |
| Tcomm |
TRUE |
communication time |
these are all variables that are measured in an experiment.
measurements
| experimentID |
variable |
value |
| 1 |
Ts |
101.5 |
| 1 |
Tp |
51.2 |
| 1 |
Tpart |
5.3 |
| 1 |
Tsync |
10.2 |
| 1 |
Tcomm |
12.2 |
| 2 |
Ts |
12356.5 |
| 2 |
Tp |
8562.6 |
| 2 |
Tpart |
256 |
| 2 |
Tsync |
5023.3 |
| 2 |
Tcomm |
2036.6 |
| 3 |
Ts |
2305.6 |
| 3 |
Tp |
805.6 |
| 3 |
Tpart |
56.2 |
| 3 |
Tsync |
12.6 |
| 3 |
Tcomm |
98.5 |
finally, for each experiment, all variables are measured and stored in
the database.
2. Entity-Relationship Diagram
The definition of the database is represented by the ERD:
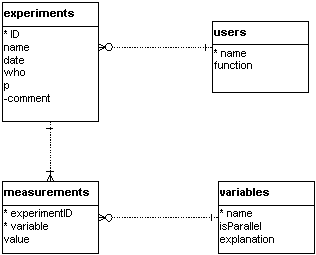 For
each table we list the columns or attributes. The attributes annotated
with a * represent the primary key of the table, meaning that the
value of the key is unique for each row (no doubles), it identifies
an entity. Attributes with a - are optional, meaning that they don't
need to be filled in, the others attributes are mandatory.
For
each table we list the columns or attributes. The attributes annotated
with a * represent the primary key of the table, meaning that the
value of the key is unique for each row (no doubles), it identifies
an entity. Attributes with a - are optional, meaning that they don't
need to be filled in, the others attributes are mandatory.
Another important feature in relational databases is the relationship
between the tables. In the experiments table, the who attribute
is a member of the users table. This connects both tables, what
is indicated with 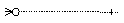 .
Moreover, we denote the cardinality of the relationship. Here, one
user will have 0, 1 or more experiments, indicated at the left side of
the connection. On the other hand, 1 experiment is performed by exactly
1 user, this is indicated at the right side of the connection. The experiments
table is connected with the measurements table with a one-to-many
relationship, but one experiment must have at least 1 measurement. So the
connection symbol is
.
Moreover, we denote the cardinality of the relationship. Here, one
user will have 0, 1 or more experiments, indicated at the left side of
the connection. On the other hand, 1 experiment is performed by exactly
1 user, this is indicated at the right side of the connection. The experiments
table is connected with the measurements table with a one-to-many
relationship, but one experiment must have at least 1 measurement. So the
connection symbol is 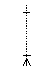 .
.
3. Database creation
The Database Definition with
CREATE
mSQL commands.
Upload this file with the
msql monitor (in a console or terminal):
msql -h 134.184.1.73 experiments_example <
ddt_experiments_example.txt
-
134.184.1.73 is the ip address of our server (infopc23), experiments_example
is the name of the database
-
the < indicates the following file is used as input for
msql
-
you don't have to redo this, I already created the database
-
for each primary key, we created a unique index
Check the definition of the database with relshow:
relshow -h 134.184.1.73 experiments_example
=> you get all the tables
relshow -h 134.184.1.73 experiments_example experiments
=> the definition of the table experiments
4. Database access
Add the data with the
INSERT statements. First start the
msql monitor
msql -h 134.184.1.73 experiments_example
mSQL> INSERT INTO users VALUES ('john', 'student') \g
Remark that the \g is to end the query and send it to
the database.
All INSERT commands to fill
the database.
Also try the
SELECT statements:
mSQL> SELECT * FROM experiments\g
5. Database access in C
mSQL provides a mSQL API library
to access the database.
Let's illustrate this with an example program, download the following
files:
Create the makefile with tmake:
tmake experiments.pro > makefile
Make the executable:
make all
Run it:
experiments
Study the code of experiments.cc, change the query, etc.
6. Data analysis
Once you have added data to the database, it is ready to be analysed for
reporting, Microsoft Excel is a good tool herefore.
But, how get the data in Excel?
-
Put your query in a file.
-
Start msql with the query file as input and an empty result file as output:
-
msql -h 134.184.1.73 experiments_example < example_query.txt > example_result.txt
-
The result file
-
Open the result file in Excel, it will use a Wizard to convert the text
file into rows and columns
-
Step 1:
-
Original data type: or you choose Delimited or Fixed width, both will work
-
Start import at row 9
-
Step 2:
-
if you have chosen 'Delimited', you should choose space as delimiter
-
otherwise, indicate the columns (put the '|' in a seperated column)
-
Step 3: here you could for example skip the columns with the '|'
Last Updated on 02/7/2002
By Jan Lemeire